Introduction
Navigating a webpage can be a frustrating experience for users, especially if they cannot easily find the information or resources they are looking for. As a web designer, it is important to carefully consider the layout and organization of your webpage, including the positioning of links, to ensure that users can easily find what they are looking for and engage with your content.
In this article, we discuss the findings of an investigation we conducted. The main investigation is on the influence of the link position on the number of clicks generated, using data from the Wikispeedia dataset. This dataset provides a unique opportunity to study the relationship between link position and clicks, as it contains a large collection of webpages from Wikipedia articles, along with information about the clicks generated by the links on those pages.
By understanding the factors that influence the number of clicks generated by a link, web designers can make more informed decisions about how to optimize the navigation on their webpages. Throughout this article, we explain the methodology used in the project and discuss the key findings and implications of our study.
Wikipedia, the Ocean of Links
Wikipedia is the world’s largest online encyclopedia, comprising millions of pages and links between pages. Starting on one article and following the hyperlinks, your journey to your destination may not be as easy as you expect. With over 6.5 million articles on the English Wikipedia, the possible paths are nearly endless and impossible for a human to calculate in their lifetime. Articles which links to many places generally cover important topics and are more likely to be visited while link surfing. The United States article , for instance, has a wave of 294 links, so be prepared for a wild ride.
Research Questions
- How to best represent the popularity of a link?
- Does the position of the link on the page influence the click through rate (CTR)?
- If so, is it possible to quantify this influence?
- If so, is it possible to quantify this influence?
Wikispeedia: What is it again?
The Wikispeedia dataset is a subcollection of webpages from Wikipedia articles, along with information about the clicks generated by the links on those pages. The dataset is of great interest for researchers to understand the way users behave, and is the one we are going to use for our investigation.
The sequence of articles that a user clicks on before arriving at their target destination is called a path. This information is used to track how users navigate through the website.
Articles
Links
Finished Paths
Unfinished Paths
Let's first discover the data
Before investigating what makes link more or less popular, let's understand the structure of our dataset. Below is a graph showcasing the overall structure of the network of articles.
The network is especially complex, as each article having in average 27.2 links pointing to another article. The article about the United-States has no less than 1435 links pointing to it... And remember that Wikispeedia is only a fraction of the Wikipedia dataset of articles, we can easily understand the complexity of the structure. Instead, let's try to only capture the most clicked articles.
The 5 Most Highly-Trafficked Articles
1.United States: 12376 clicks
2.United Kingdom: 5565 clicks
3.Europe: 5303 clicks

4.England: 4413 clicks
5.Earth: 4172 clicks
So, let's try to dig in and understand why these articles are the most popular ones. The focus of this article is really to investigate the impact of the position of the links within a page. So let's look at that by plotting the density map highilighting where the clicks are usually done.
So, are we able to compare the popularity of articles based on their number of clicks? Well, the answer is no. We should notice that there is a bias in our reasoning. If we focus on the number of clicks, we miss an important covariate: the number of links pointing to an article can probably greatly influence the number of clicks. In other words, links which have a very high number of impressions will probably be the ones which are the most clicked on regardless of their position. And looking at the top articles in terms of impressions, this seems indeed to be the case.
We can easily verify that. In web analytics, there is one metrics which is exactly made for that: the impressions! These refer to how often the links have appeared on the journeys of all players.
So unsurprisingly, the ranking is roughly the same as above. Links which are the most often clicked may only be the ones which appear the most often. We need to go beyond this analysis.
Fortunately, there is one metrics much more relevant than the number of clicks that is here to save us: the Click-Through Rate (CTR). It corresponds to how many clicks are generated for each impression.
Now, if we rank the articles according to their CTR, and we omit the outliers with very low number of impressions, we get
That's much more interesting. So, why are these links the most popular ones? This is what we are going to figure out in the next part...
Digging Into the Structure of the Wikispeedia Data
Now that we have well defined our target metric, let's continue our investigation: do users take the time to go through all the articles, or do they prefer to click on the very first links that appear on the page?
It would seem that indeed, links on top of the pages are among the most popular. Another way to visualize this relation is by performing an ordinary least squares regression (OLS). As a result, we obtain the following regression plot:
Again, we see that in general, links positioned on top tend to have a higher CTR. Of course, this is just a superficial analysis and we can’t draw valid reasoning from it. ADA students don’t just jump to conclusions!🏊 As we are handling data which is outside our control, we should definitely talk about observational studies.
Observational study
Throughout this study, the links which are at the top of the page are called “treated group" and the links which are at the bottom of the page are called “control group”.
Source article length
Links do not have identical probabilities to be at the top of an article. In fact, its probability depends on the length of the article in which it exists. If the source article is long, the probability of a link to be at the top decreases. At the same time, its probability to having a high CTR also decreases, as it may be harder for users to scroll through the content, and the link has higher chances to be buried deeper in the article. On the other hand, if the source article is short, the probability of a link being at the top increases. But also, its probability to have a high CTR increases. Let’s take a closer look at the data and compare the distribution of the source article length in the control and treated group.
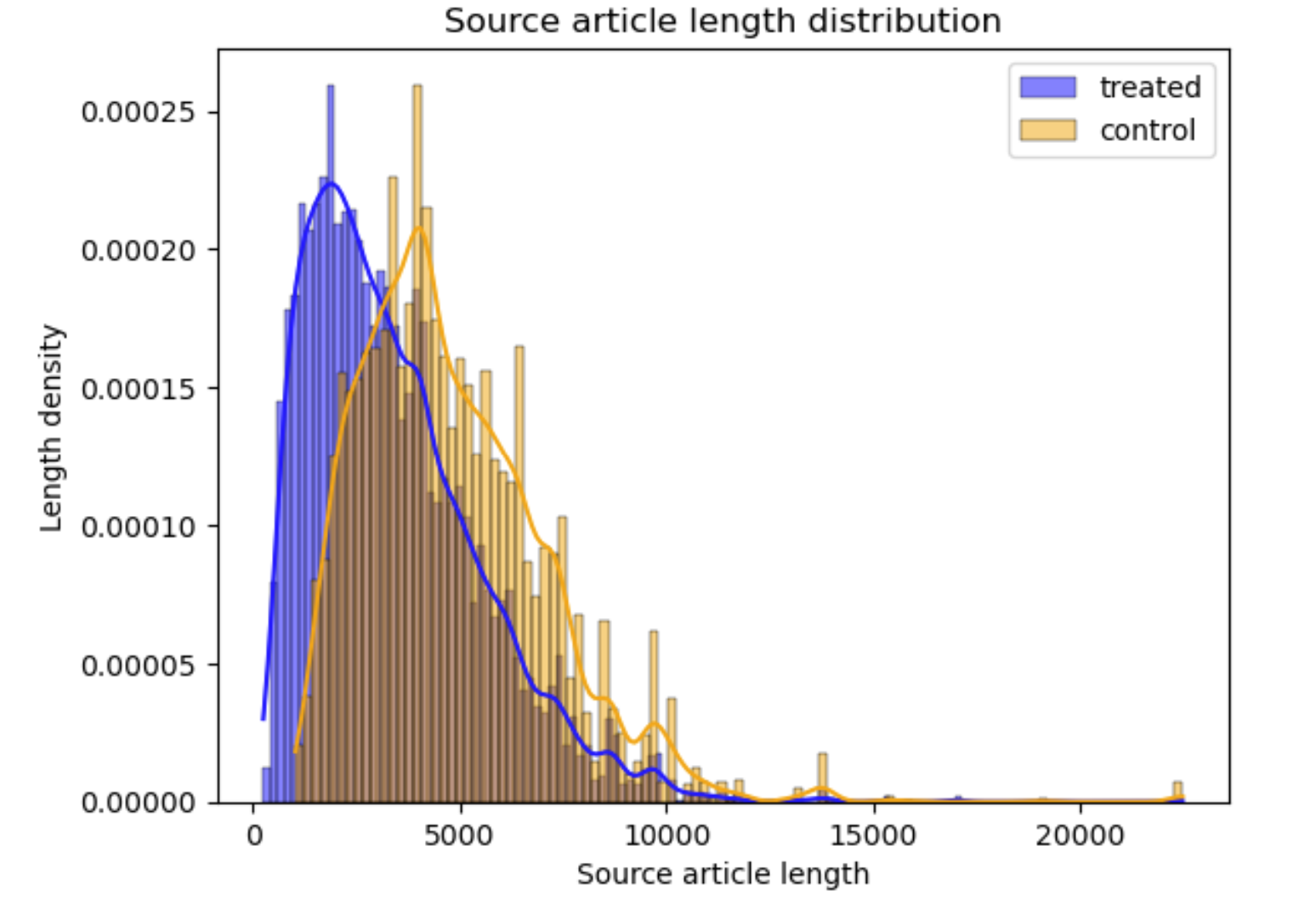
Interesting! So, the source article length distribution is different in both groups. Thus, not all links have the same probability to be at the top of an article since it depends on the length of the article in which they exist.
Hold on! We are not done yet with confounders! The position of a link is not only affected by the length of the source article, but also by the topic of the source. It's time to use our exBERTise to examine the semantic similarity between the source article and its links and see how it relates to the link's position.
Semantic textual similarity
Let's take a closer look at the data distribution.
Don't be surprised by the vertical lines we obtain, they just correspond to links displayed in the same page (at the very right, all points are links present in the United-States article). What's much more interesting is to see which are the links at the top left part of the plot: these are the ones with the highest CTR. Use your mouse to see to which source and target article they correspond to. For instance, the link going from the page "Communication" to the page "Telephone" has a very high CTR of 0.67. Why can this be the case? Well, maybe because the two articles are very close conceptually speaking. This leads us to think of a new confounder: the semantic distance.
The logic behind this analysis is the following: if the Wikipedia page is about a specific topic, the links which are at the top of the page are more likely used to define or explain the topic. Therefore, the semantic similarity between the source article and the links acts as a confounding factor in our study.
Handling textual data leads us to explore Natural Language Processing tools aiming at extracting meaningful data. Semantic similarity is the task of assessing the textual semantic similarity between two sentences. For each source/target article, a similarity score is assigned to each pair. The BERT model was used to generate encodings and the cosine distance was used to caluclate the semantic similarity. Now, let’s visualize the distribution of similarity scores in both the treated and control groups.
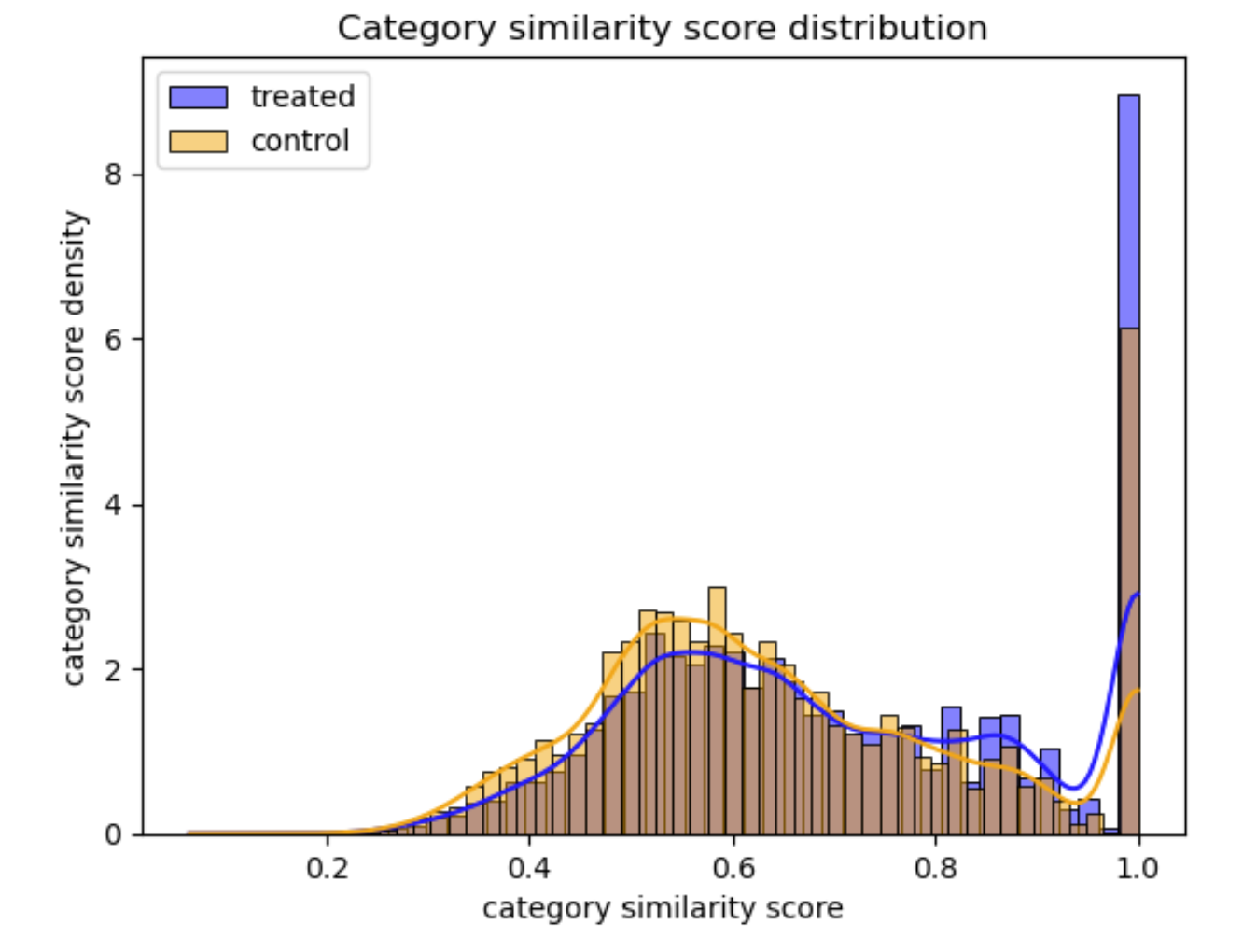
Alright! It seems that depending on the semantic relationship between a link and its source article, its positioning changes.
Propensity score model
Here, we assign to each source/article pair a propensity score, which is the link probability to be at the top of an article given the covariates:
- Source article length
- Source article topic
Balancing the data via matching
Now, we can compute the matching between the two groups. Since the probability that two rows have identical propensity scores is negligible, we use an approximate matching by implementing a K-nearest neighbors model to the data. In other words, for each link, we aim at finding its K neighbors with respect to their propensity scores within a certain radius. Next, each treated link is matched with a link from the control group such that it is one of its neighbors and it has not been matched yet. Now that our data is matched, let’s compare again the CTR distribution between the treated and control groups.
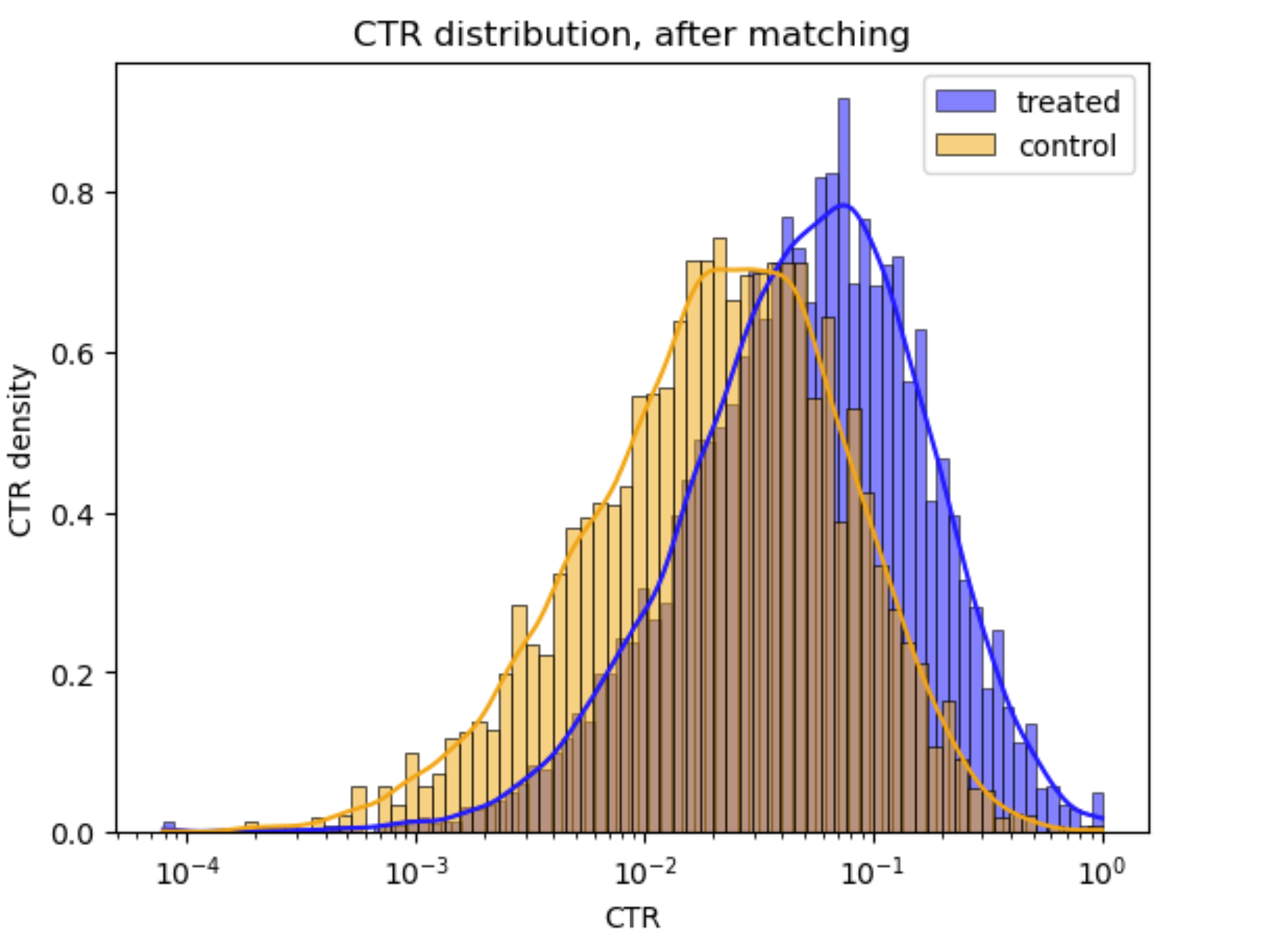
Alright! The distribution is not very different from the one we had before the matching. We redo the linear regression between the link position and its CTR and we find a significant coefficient of -0.2.
Again, this coefficient is nearly the same as the one we found before matching. This could indicate that the confounders we set are not significantly influencing the relationship between the position and the outcome variable, the CTR. Thus, the matching could be improved by making sure that we match links that are in the same source article.
Let’s push further
Another one! let’s visualize the new linear regression
It seems like even after fixing the source article, this latter did not result in a stronger relationship between the position and the CTR.
Conclusion
Based on the above findings, we can conclude that there is a significant correlation between the position of a link and its CTR. However, we did not find any imporvment when we addressed the potential influence of confounders.
In fact, the matching did not improve the linear regression results. This could be due to the fact that an unobserved confounder is still present. The most suspectible confounder is the characteristics of the users who click on the links. Since the data of Wikispeedia was collected by users who are motivated to win
the game thus, they are more likely to search intensevely for the links. Other characteristics of the users could also be a confounder, such age, education, etc. Since we do not have access to this data, we cannot control for it.
As outlined in our research questions, we aimed to understand the impact of the position of a link on its CTR in order to improve the navigation on a Webpage. Our results are relatively encouraging since we found that the position of a link is a significant factor in determining its CTR.
All these findings are based on the data collected from Wikispeedia game so it is important to be cautious about the similarities and differences between Wikipedia articles and standard webpages. Wikipedia, articles for example, the links density in Wikipedia articles is much higher than in standard webpages.
Other factors that can influence the CTR of a link are the link font, layout, color scheme, etc. These factors are not included in our study and can be explored in future work.
Future Work
Based on the conclusion of our study, the limitations of Wikispeedia dataset and the lessons learned through this work, we can suggest the following future work to improve the article findings:
1. Make the observational study stronger by adding new covariates and test them with multiple setups.
2. Expand the dataset by using Wikipedia traffic data instead of Wikispeedia data.
3. Generalize the findings to standard webpages. Webpages can collect data with more features which can make the study stronger.